


Learnings from a few years helping customers to build and run cloud native platform using Azure Kubernetes Service
07 Jun 2021 in DevOps | Kubernetes | Microsoft AzureOver the past years, I have been working with customers to help them build and run a cloud native platform on top of Microsoft Azure using Kubernetes. I have learned a lot and I think this is a good time to write down and share all these learnings.
The following contains a lot of information about all the points I think are very important to discuss and think about if you are working on building a cloud native platform for your company. I have not gone into implementation details for this post but I made sure to include a lot of external links to make your life easier going deeper in every topic.
You can see this post as an accelerator or agenda of the architecture/design discussions you should have before starting your project.
Let’s start by understanding what is a cloud native platform.
Cloud Native Platform, what does it mean?
The Cloud Native Computing Foundation (CNCF) provides one official definition of what means “cloud native”:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
The idea behind this is to try to codify and unify the way to build, deploy and run enterprise applications. There are more and more companies trying to build a consistent platform across teams and clouds (public, private or hybrid) to ensure they use the same tools and process to deploy, run and operate all their applications.
Application developers don’t want to care about where the application runs it could be in a private or public cloud. They don’t want to have to implement behaviors in the applications because it can run in different places. As well as a DevOps operators don’t want to have different way of packaging, deploying and operating applications across the company, depending on where they are actually running.
Building a platform that targets multiple teams (and sometime multiple clouds / locations) is not an easy task. It’s a trade off between going with full managed 1st party technologies (most of the time available as PaaS/SaaS, so easy to use / operate), and cross-platforms technologies coming from the cloud-native landscape. The ultimate goal is to abstract the underlying platform from your end users (applications developers and operators), but also make sure you do not take any architecture decision that could be influenced by how you designed something on another cloud or on-premise.
No doubt that Kubernetes is the central piece of cloud-native platform, as it is designed to provide abstraction of the infrastructure on top of which it is running. Kubernetes comes with a complete deployment and development model to ensure that applications running in Kubernetes do not have to know or interact with the actual machines they are running on, or about network, persistent storage, security boundaries they are using.
The goal of this article is not to go into details about the application layer itself and how to deploy applications inside a Kubernetes cluster. There is already tons of articles and documentations about that. If you want to know more about how to get started with application development/deployment with Kubernetes on Azure, you can start from there.
As mentionned in the introduction, I will go over a lot of different topics that I think you should consider and discuss before going into Azure Kubernetes Service deployment. But first thing first… let’s discuss briefly about where it all start: the landing zones…
Landing Zone
This is important to have close collaboration between the teams responsible for the landing zone, the teams responsible for deploying and operating Kubernetes and applications teams. Indeed, a lot of architecture design decisions that are taken on one side have some impact on the others. This is the reason why I decided to write a small paragraph about it before going into the Azure Kubernetes Service topics.
All begins with a landing zone: this is the basic infrastructure where the platform will be deployed. It includes components such as Azure subscription, network topology and connectivity (express route, firewall, vnet, route tables, dns configuration…), identities and role-based access control, business continuity and disaster recovery.
Read more about Azure Landing Zone here, part of the Cloud Adoption Framework documentation.
Landing Zones are mostly about automation with intensive use of infrastructure as code (ARM template, Terraform, Bicep…) to make sure it’s possible to create a new one quickly and easily, in an automated and reproductible way.
There are different types of landing zones implementations documented in the Cloud Adoption Framework. Often, you will have something like hybrid connectivity with hub and spoke, essentially because it allows to connect multiple landing zones to on hub that is connected to your existing network:
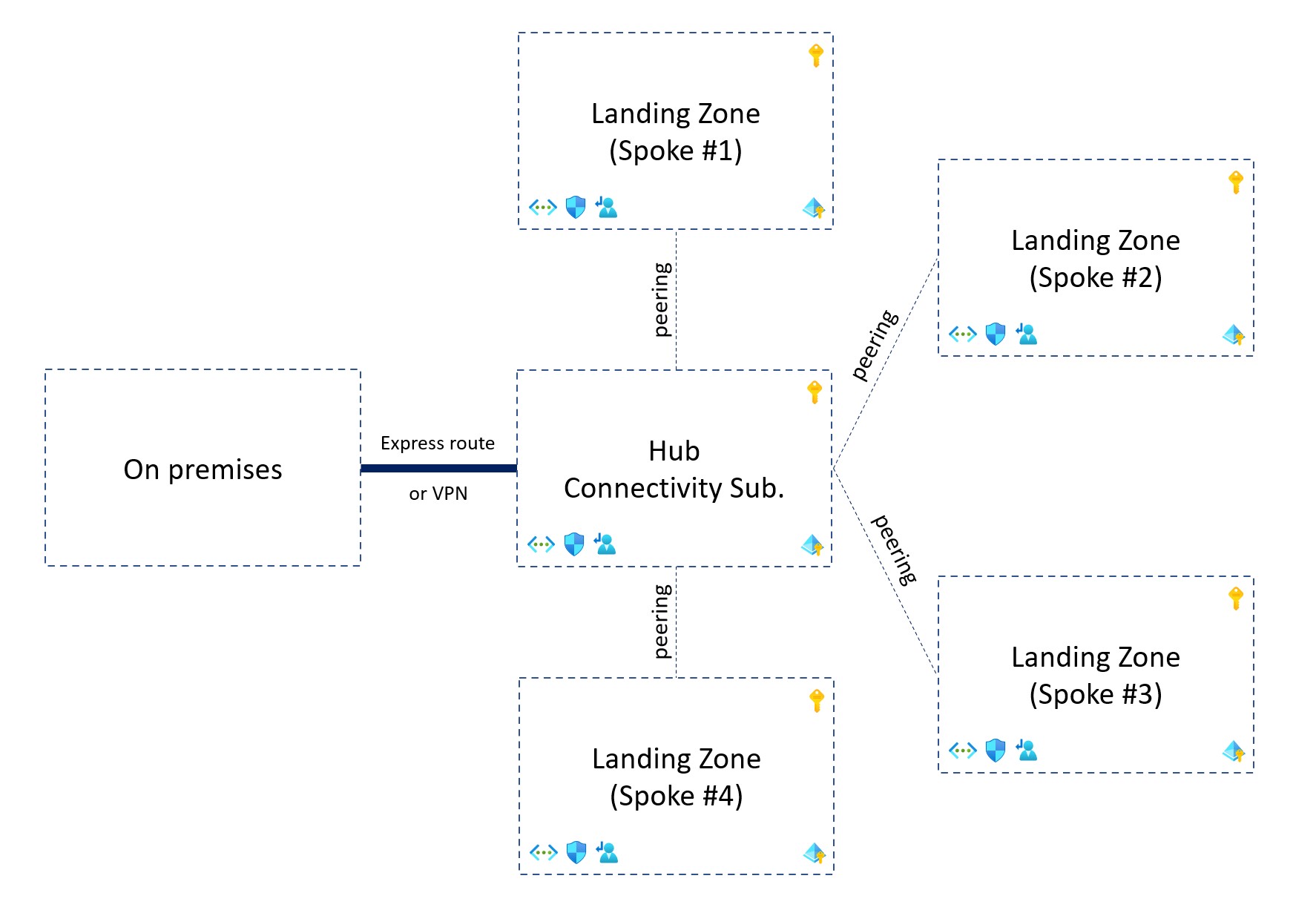
Zooming on the network topology of one landing zone could lead to something like the following:
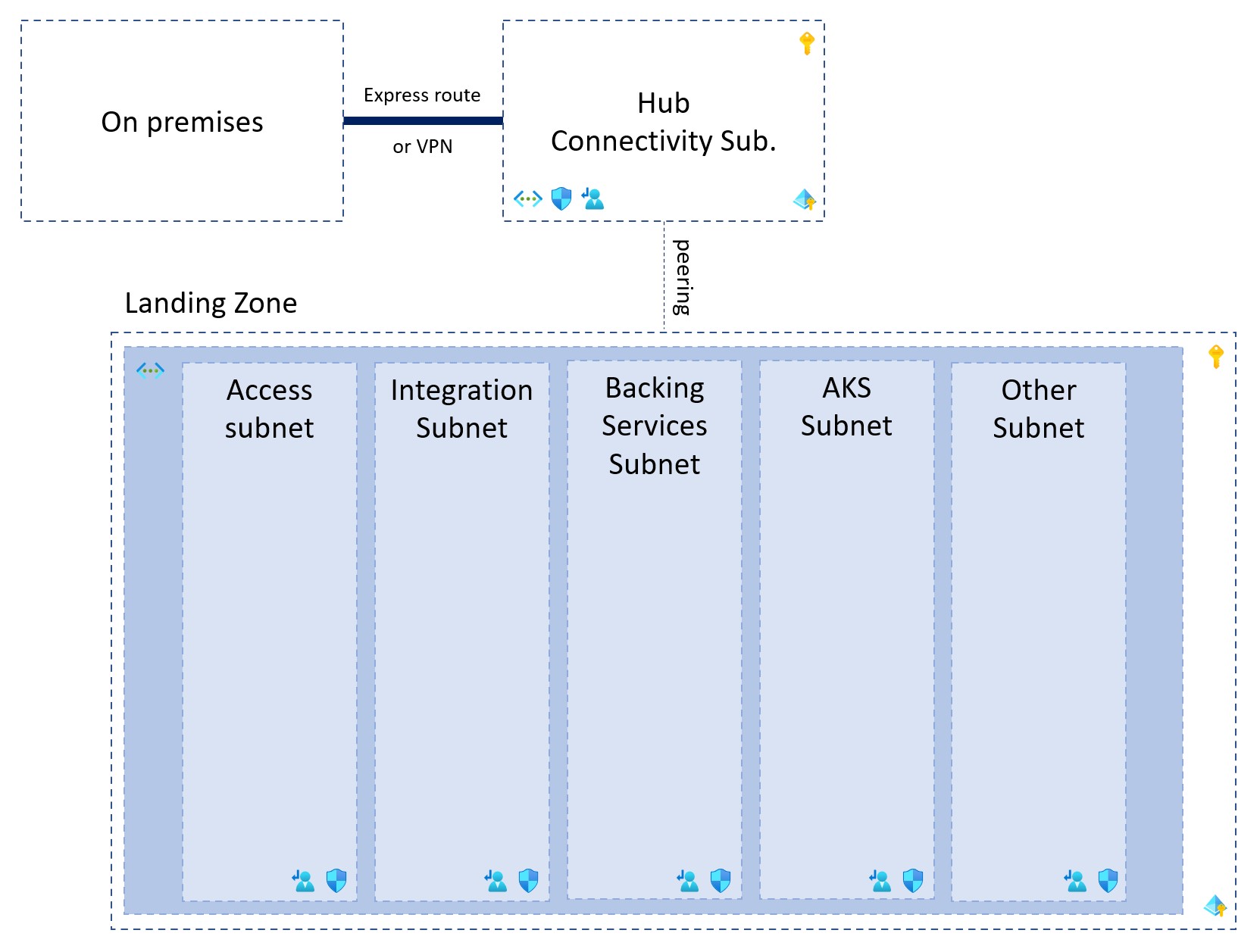
Obviously, the network topology will vary depending on your needs, but the principles will stay the same. Let’s consider we have the following network topology. Each and every “cloud native platform” landing zone define a virtual network with a peering connection to the hub. This virtual network contains a bunch of subnets:
- Access subnet: this is the only subnet that is accessible from other spokes / landing zone. It is the network entry point of the landing zone. It can contain jumbox server, Azure DevOps/Jenkins agents etc.
- Integration subnet: this is the subnet where private endpoints from “external” managed service will land. For example, if you are using Azure Storage, Azure Container Registry or Azure KeyVault - these services can get a private IP address on the landing zone virtual network, in this integration subnet.
- Backing Services Subnet: this is where any backing services (data stores, caches, message brokers) can be deployed.
- AKS Subnet: this is the subnet or subnets (if multiple clusters deployment) that will be used by Azure Kubernetes Service.
- Other Subnet: any other subnet you need in the landing zone.
Azure Kubernetes Service (AKS)
The landing zone is ready, let’s talk about Kubernetes.
Private Cluster Deployment
In this kind of cloud / network topology, it’s a common practice to deploy Azure Kubernetes Service using the private cluster feature. It will make sure that the cluster has not public endpoint and is reachable only from a subnet in the landing zone virtual network.
When you chose this deployment mode for AKS, you end with:
- no public endpoint for the cluster-api (the endpoint that is used by
kubectlto manage the cluster) - a private endpoint with a private IP address on the subnet targeted by the AKS deployment (use one subnet per AKS cluster)
Deploying a private AKS cluster does not mean that you cannot have a public endpoint for your applications running in the cluster. It means that the Kubernetes management endpoint (api server) is private and reachable only from a private endpoint in a given subnet (ex: access subnet).
In addition to this private cluster deployment, you might have additional network rules that forces the traffic to go through a firewall (in Azure or on-premises) or block Internet access for some resources. Azure Kubernetes Service requires that you open access to some well-known resources in order to be able to intialize and pull some container images, security patches etc. All you need to know about restricting AKS egress traffic is available here.
Azure CNI vs Kubenet
I think I had this conversation with every customers I helped deploy Kubernetes on Azure over the past years. Let me try to make it easy.
TL;DR: If you don’t have any IP addresses usage restrictions (lucky you are!), don’t even think about this and stay with Azure CNI, the default option. Consider Kubenet only if you need to save/reuse IP addresses between environments.
Azure Kubernetes Service supports two plugins for networking: Kubenet or Azure CNI. In short:
- Kubenet will allow to reuse IP CIDR between cluster, as it will create a dedicated private network for pods running in each cluster and use NAT to ensure communication from/to the outside of the cluster. Only nodes and (private) exposed services will get an IP address on the AKS subnet
- Azure CNI will allocate an IP address from the AKS subnet for each and every pod, in addition to the nodes and (private) exposed services.
You can read more about Azure CNI vs Kubenet on this page and understand what are the constraints and restrictions you might have when using Kubenet instead of Azure CNI, in case you have to.
Cluster identities and separation of concerns
Identity management is an important piece of your platform. When working with Azure Kubernetes Service, you can apply separation of concerns principles by providing different identities for different puroposes, the most common being:
- AKS Cluster Identity
- Kubelet identity
- Azure Active Directory Pod identity
There are other use of managed identities with AKS, depending on your scenario and the add-ons you are using. You can find some documentation on this page.
AKS Cluster Identity
This is the identity that will be used by Azure Kubernetes Service for all tasks related to Azure-platform integration, like VNET integration, route tables / NSGs updates, Azure Disk/Storage operations for persistent volumes etc. This identity can be a Service Principal, a User-Assigned Managed identity or a System Identity. In the first option, you can let AKS create it for you or bring your own-one.
Kubelet identity
By default, Kubelet will use the identity provided for the AKS cluster for pulling images from an Azure Container Registry. In some cases, you might want to overrides the Kubelet identity to give an identity that is authorized to access only an ACR, and that has no other permissions required by AKS (like Storage or VNET integration). You can use the Bring Your Own MI for Kubelet to do that.
Azure Active Directory Pod Identity
Azure Active Directory Pod Identity is a component that you can run inside an Azure Kubernetes Service cluster to enable your applications to use managed identity to access external Azure resources. Imagine that you have a Web API running in Kubernetes that needs to access an Azure SQL Database. You don’t want to store credentials in a Kubernetes secret or an environment variable. Pod-identity allows the pod running your application to work with managed identities and access the SQL Database using it.
This component can also be used by the Secret Store CSI Driver and let Kubernetes read secrets directly from an Azure KeyVault.
Azure Active Directory Integration
Azure Active Directory integration is a different concept from cluster identities described above. It is related to how your Kubernetes users will connect and interact with the cluster and cluster API. It’s possible to integrate Azure Kubernetes Service with Azure Active Directory and make sure that you manage authentication and authorizations in the cluster using Azure Role-Based Access Control (RBAC).
Once configured, you can use principals object ids or e-mails and Azure AD groups object ids to define Kubernetes-RBAC rules to allow users to access a given namespace or resource inside the cluster. This means that the first time users will do a kubectl on a AD-enabled AKS cluster, they will be asked to connect to they Azure account.
For everything related to non-interactive login, like automation pipelines deploying applications inside Kubernetes, you can use kubelogin.
Instead of writing your own Kubernetes-RBAC manifest referencing users and group object ids, you might also want to enable Azure RBAC support for Kubernetes, which let you assign Kubernetes-specific roles to Azure principals and groups.
Secrets Management
Applications running in Kubernetes need secrets. By default, when you create secrets in Kubernetes, values are stored in Kubernetes data store (etcd). When using Azure Kubernetes Service, Etcd store is fully managed by AKS and the data is encrypted at REST. This is also true for all Kubernetes secrets.
You might want to store your secrets in an Azure KeyVault and be able to read them directly using the secret Kubernetes API, to use the same manifests for your workloads. This is what will provide the CSI Secrets Store Driver for AKS.
Kubernetes upgrades, patches etc.
Keeping the different components of the platform you are building up to date is critical. First to ensure the first level of security patching, but also to allow you user to continue to innovate and benefits from the new additions of Kubernetes.
Kubernetes is a platform that evolves quickly and that is always bringing new features for application developers and operators. It is important that you include in your service the ability to choose what version of Kubernetes people want to run, and that you provide a migration path between versions.
Applying security patches, upgrading node images version or Kubernetes version will lead to virtual machine evictions and reboots. In order for your customers’ workloads to continue to work correctly, it’s important that your operators’ users have a good plan for availability, using Kubernetes pod disruption budgets. You can read more about this here.
Security patches
Kubernetes relies on virtual machines that run an OS, Ubuntu or Windows Server (for Windows pools), when speaking about Azure Kubernetes Service. It’s important that these virtual machines get the security updates in a continuous fashion. When you deploy an AKS cluster, the underlying VMs running in the nodes scale sets are automatically configured to retrieve these updates. But sometimes, VMs need to be rebooted. You can do it manually or use Kured, a deamonset that will monitor nodes and detect when they need to be rebooted, following Kubernetes best practices (codorning, draining etc.)
Node images upgrades
When the AKS team releases new features, they also release new OS images. These images also come with the latest security patches for the underlying OS.
If you upgrade the Kubernetes version of your cluster (see next section), you will automatically get the latest version of the underlying OS. But if you don’t, you will stay with older version. It’s possible to force the node image upgrade using the Azure CLI, as described on this page.
Kubernetes version upgrade
Kubernetes version upgrades should be an easy self-service operation provided by the platform, and it should not be forced for your users, apart if they are running an unsupported version of Kubernetes.
When updating the version of Kubernetes in Azure Kubernetes Service, you must ensure that the control plane (master nodes) are running a version that supports the targeted version (usually equal or upper). If it is not, then you must upgrade the control plan first.
Once the control plane has been updated, you can choose between updatinng all your node pools or only some of them. This is also called in-place Kubernetes upgrade.
During node pool upgrade, AKS will codorn an drain node one by one in the underlying scale set and replace them with a node running the new version of Kubernetes. You can control how many nodes are updated at the same time using the surge parameter.
Again, the workloads you are running in AKS must be designed to work with this kind of operations where node are rebooted / evicted.
Another approach could be a blue/green deployment at the infrastructure level: deploy a complete new AKS cluster in the targeted new Kubernetes, migrate workloads, run tests and then switch the traffic to the new infrastructure.
You can read more about patching and upgrade guidance in the day-2 operations guide of the Azure Architecture Center.
Cost optimization
When building a platform in the cloud, cost management and cost optimization are important topics. Azure Kubernetes Services has some features that can help you to optimize costs, for example by turning off unused clusters, like development/tests environment, when they are not used or by using spot VMs.
Azure Kubernetes Service - Start/Stop cluster
AKS supports multiple pools for a single cluster. It allows you to mix SKU, scale pools differently depending on the workload they are running, share clusters but isolate workloads between teams, business units etc. AKS supports System and User pools. System pools are dedicated to run critical Kubernetes components (dns, metrics server etc.) and User pools are dedicated to run your applications. Every AKS cluster must have at least one System pool. If you have only 1 pool in your cluster, the System pool will also run your applications.
AKS supports scaling User pools to 0 (i.e. the underlying VM scalesets contains 0 node) but it’s not possible for System pools. You might have environment that you want shutdown when they are not used, to reduce the cost of your platform. You probably don’t need to have development and test clusters running outside of working hours. This is where the Start/Stop cluster feature becomes useful: it allows to completely deallocate all compute resources for a given Kubernetes cluster.
Using two simple commands:
az aks stopwill stop a running clusteraz aks startwill start a stopped cluster
Together with a scheduler system (ex: a bash script with a CRON or a scheduled pipeline in Azure DevOps, for example), you will be able to schedule when you want some AKS cluster to be stopped and when you want them to be started again. There is another well-documented example of scheduling start/stop of AKS cluster using Logic Apps by Thomas Stringer.
Azure Kubernetes Service - Spot Virtual Machines
Spot Virtual Machines are intended to optimize costs. It allows to benefits from the Azure unused capacity at low cost. The drawback of this is that it comes with no SLA and machines can be evicted at any time if Azure needs it back.
AKS supports Spot VMs by offering to create a Spot node pool. One way to see this feature is “built-in chaos-engineering at low-cost” :-).
Of course, before using it you must ensure that your workloads running on these kind of pool will be designed to support it, as a virtual machine from the underlying scale set on which a given pod is running might be evicted at any time. You can read more about eviction policy here.
Observability
Observability is a central piece of any system. There are different ways to implement observability on Azure Kubernetes Service based platforms. You can go with the Azure built-in stack like Azure Monitor, Logs Analytics etc. Or you can decide to plug external tools like Prometheus, Grafana or ELK…
If you build an Azure-only platform, I would recommend to go with the first option, as you will get everything you need very easily. If you are building a platform across multiple clouds then the second option is probably better for you. You want to have the same dashboards, the same alerts, and the same observability practices for your platform even if they are running at different places.
Azure Monitor and Container Insights
Azure comes with everything you need to setup observability for your platform in a built-in and easy fashion, using Azure Monitor and Container Insights. It will give you all what you need in term of monitoring the containers running inside the cluster, resources usage like memory and CPU etc.
When enabled, you can get all these information directly from the Azure portal, and browse your cluster using a nice dashboard (this replaces the deprecated regular Kubernetes dashboard).
Like mentionned before, when you build a platform it’s not just about Kubernetes. Even if it is a core piece of the platform you will probably run some other services in Azure, like message brokers, virtual machines, managed databases like SQL Server or PostgreSQL, for example.
All these resources comes with native integration with Azure Monitor. It will provide you one unified monitoring interface for all your needs. You can even extend the experience to the application/workloads running on the platform by suggesting to application developers and operators to use Application Insights.
Other tools
If you have chosen to rely on other tools like Prometheus, Grafana or ELK for observability, there are some interesting pieces of integration with Azure to mention here.
Azure Monitor third parties integration
First of all, you can benefits from all the data from Azure Monitor and visualize it directly from Grafana, using the native Grafana Azure Monitor DataSource plugin. When doing that, all the monitoring data will be collected and stored into Azure Monitor and Grafana will be able to connect to Azure monitor to extract the data and display it.
When using external stores for logs and metrics, you might want to be able to extract data from Azure monitor for platform services. This might be even more important if you are building for multi-cloud. You probably don’t want to have different tools for observability.
- If you need to store metrics into Elastic Search you might want to have a look to Metricbeat to extract from Azure Monitor and import to Elastic Search
- If you need to store metrics into Prometheus then you can use Promitor to scrap automatically metrics from Azure monitor and import them into Prometheus.
Azure Logs Streaming
Azure has standard support for streaming diagnostics the logs of every service into a dedicated storage account or Event Hubs.
From this, it’s possible to use a components like Filebeat that will take the Event Hubs stream has input and will output it into Elastic Search.
You can read more about Azure observability with Elastic on this page.
Conclusion
I hope you enjoyed the reading and that this article is helpful to understand all the elements to consider to run a cloud native platform based on Azure Kubernetes Service. Having a secured and enterprise grade deployment of AKS is only the begining of the adventure. From there, you will be able to benefit from all the inovation of the Kubernetes and Azure ecosystem.
Indeed, it has been announced during Build 2021 that it is possible to go a step further into building a cloud native platform for your applications developers and operators, using Azure Arc. Services like Azure App Service, Azure Functions, Azure Logic Apps, Azure Event Grid and Azure API Management can run on top of any CNCF-conformant Kubernetes cluster, on Azure, on-premises or any other public cloud. This is a new step in managing from one central point all your clusters and propose a consistent cloud native platform to your users. You can read more about this new capabilities on the Azure Blog or also in this excellent article from Tom.
Have fun with Kubernetes!